A few years ago I noticed that a LOT of my slack messages were repetitive. There were common phrases I used a lot (if I remember correctly) and common first steps for tasks or questions I was asked (can you post a screenshot?). If the next few words I’m going to write are obvious, why do I even need to write them?
 Fig 1. What I type vs what gets displayed
Fig 1. What I type vs what gets displayed
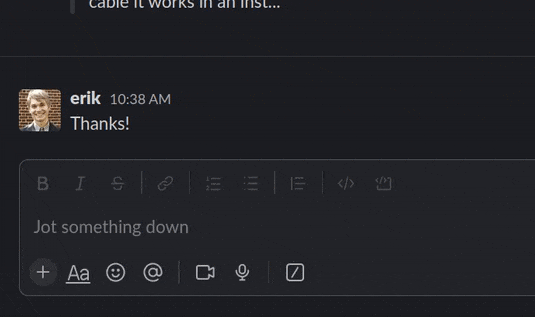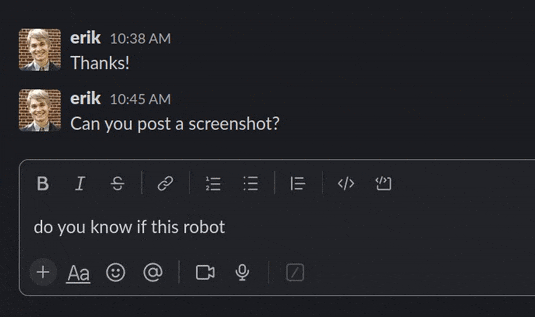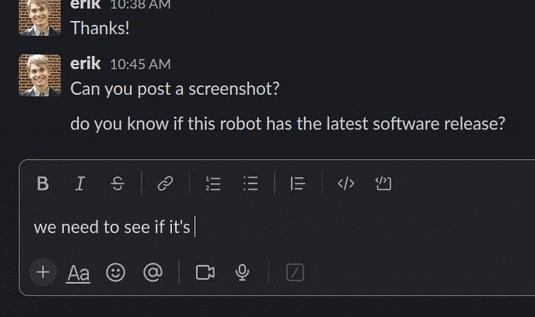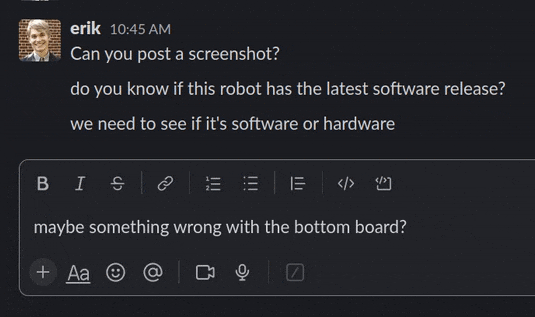 Fig 2. Debugging robots even faster now!
Fig 2. Debugging robots even faster now!
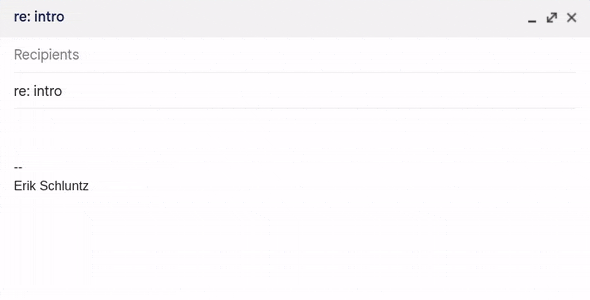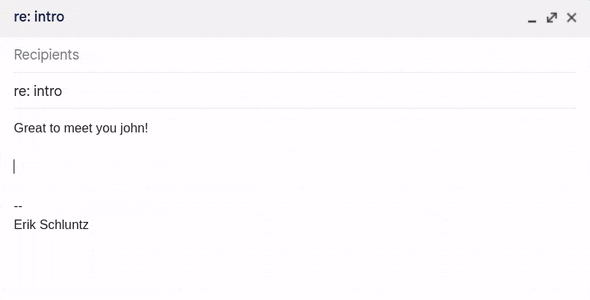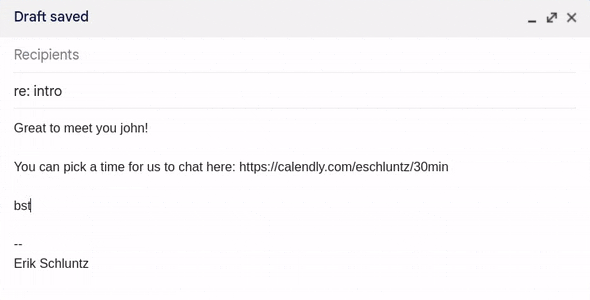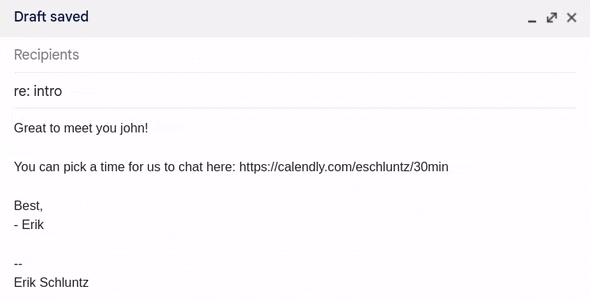 Fig 3. Using my shortcuts in Gmail.
Fig 3. Using my shortcuts in Gmail.
How does it work?
My first step was to figure out just how predictable and low entropy my writing is. I exported a data dump of the last 6 months of our company’s public channel slack history (CTO perks) and wrote a script to parse my own messages into a corpus of text. This gave me 15 thousand lines of my writing to analyze!
srm. Slack data exports only contain public channels, so there’s no private information that I saw. 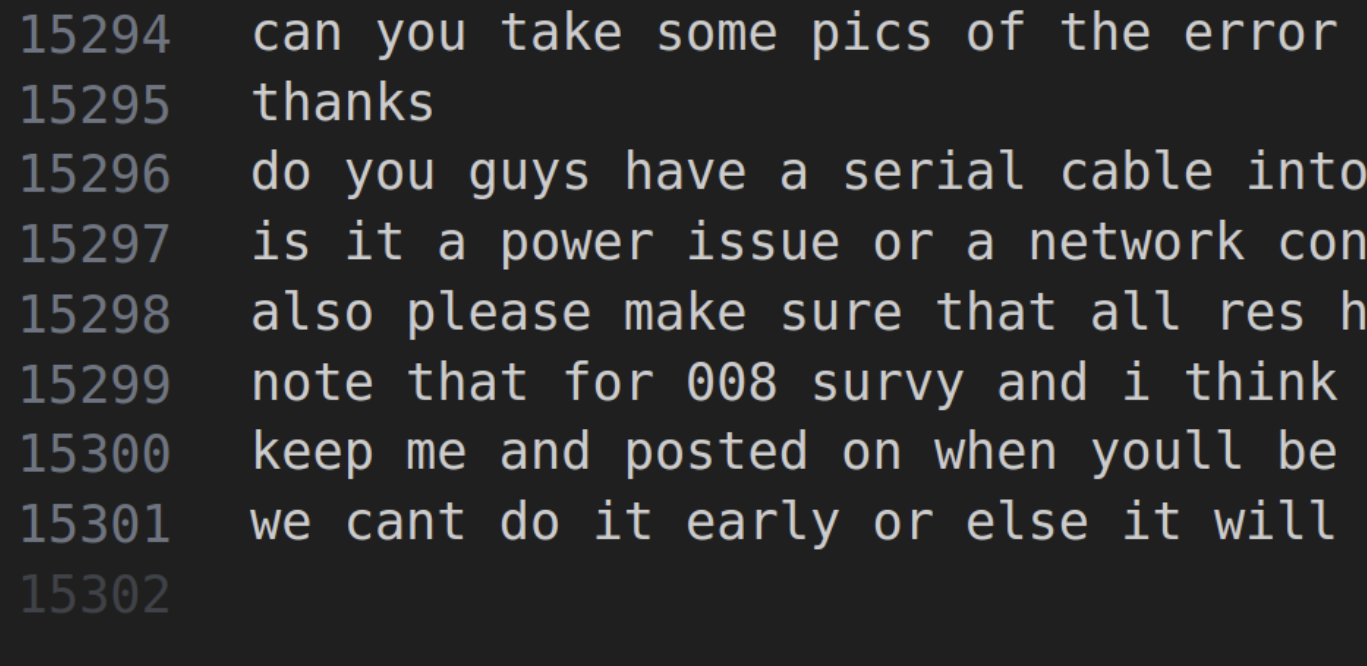 Fig 4. A sample of my slack messages with all punctuation stripped out. Yes… I spent a lot of time helping people debug robots…
Fig 4. A sample of my slack messages with all punctuation stripped out. Yes… I spent a lot of time helping people debug robots…
Finding Repeated Phrases
The next step is to look for frequently repeated phrases! I broke up my corpus into N-Grams of different lengths and then counted how many occurrences each n-gram has in my writing. Most people pick a particular “N” for their n-grams, but I’m actually looking for repeated phrases of any length, so I used N=1-5 and combined them.
 Fig 5. An example of how a sentence is broken down into different length n-grams. This sentence produced 15 different N-Grams to count and look for in the rest of the corpus.
Fig 5. An example of how a sentence is broken down into different length n-grams. This sentence produced 15 different N-Grams to count and look for in the rest of the corpus.
This got me my list of most commonly used phrases! Unsurprisingly, the top of the list is mostly 1-grams, with “the” taking the top place with 9,933 occurrences in my writing. The most common 2-gram is “in the” with 755 occurrences.
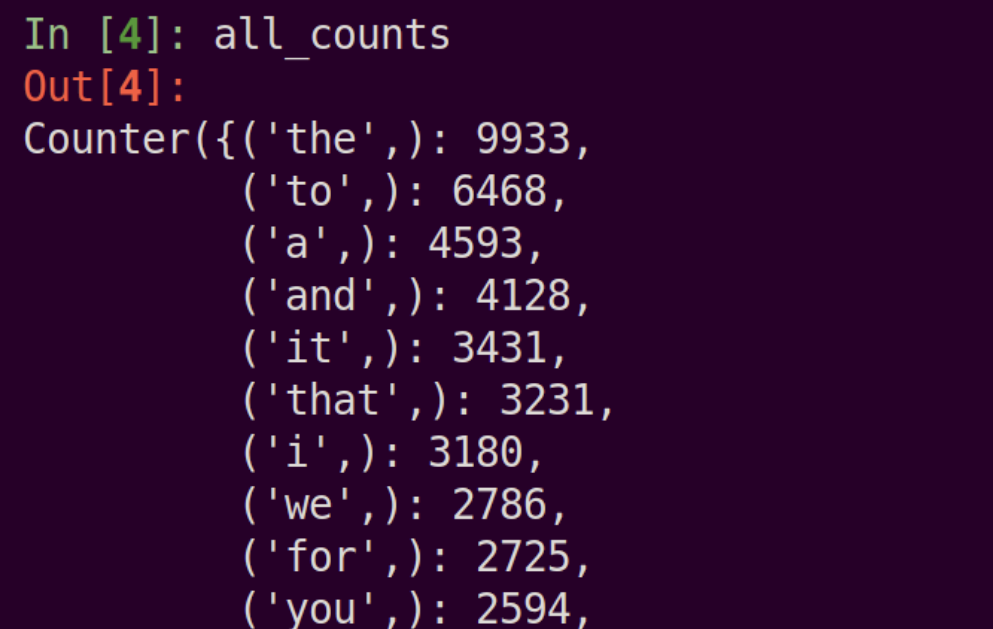 Fig 6. My most common n-grams.
Fig 6. My most common n-grams.
But the goal here is to shorten text! There’s not much I can do to shorten typing “i”, is there? I need to weight each of these n-grams by its length, so I know how many characters in total I can save. Actually, I want to weight them by length - 2 to account for the length of the abbreviation that I will type instead.
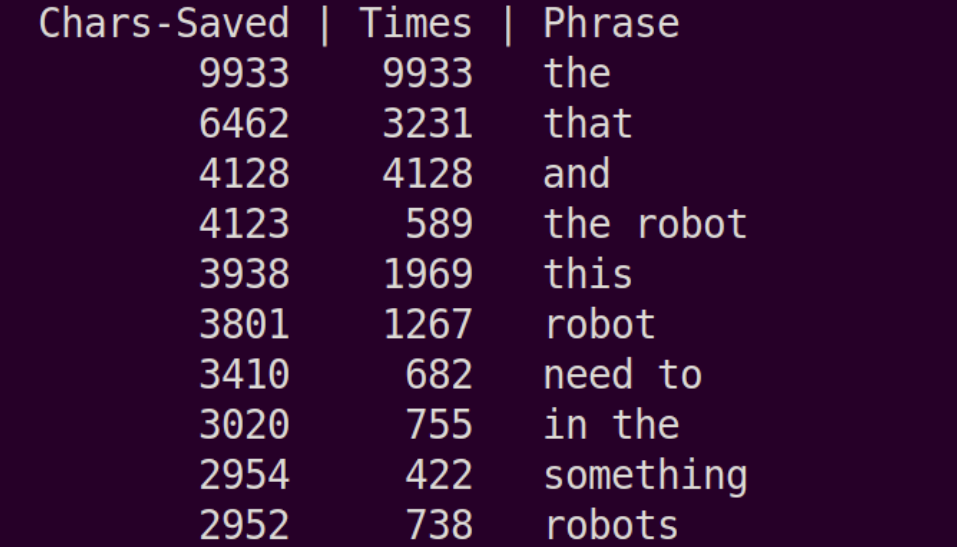 Fig 7. Top phrases to reduce characters, if replaced by a 2 word abbreviation.
Fig 7. Top phrases to reduce characters, if replaced by a 2 word abbreviation.
Interestingly, “the” is still top of the list even if an abbreviation would only save a single character! We also have some longer phrases here like “the robot” and “something” that occur less frequently, but are weighted highly because of how many characters can be saved by abbreviating them!
Choosing Abbreviations
Ok, now that I know what phrases I want to abbreviate, what should I actually replace them with? My abbreviations needs to:
- Not cause problems with other things I write.
- Not overlap with each other.
- Be easy to memorize.
- Be as short as possible.
For #1 I thought I could just do a dictionary look up to blacklist any english words. That works great for preventing and -> a, but it turns out I type plenty of things that aren’t officially english words, like “yc” (aka Y-Combinator). On the other hand, “bat” is an english word, but I typed it exactly zero times in my 6 month data set, and it makes a very memorable abbreviation for “be able to”, which is one of my commonly typed phrases.
The proper way to do this would be to use the frequency in my corpus of text to classify whether a given abbreviation is “available” or not. I started with a simple hardcoded blacklist of terms to avoid, and it worked so well that I haven’t had to revisit the problem. Always good to start simple!
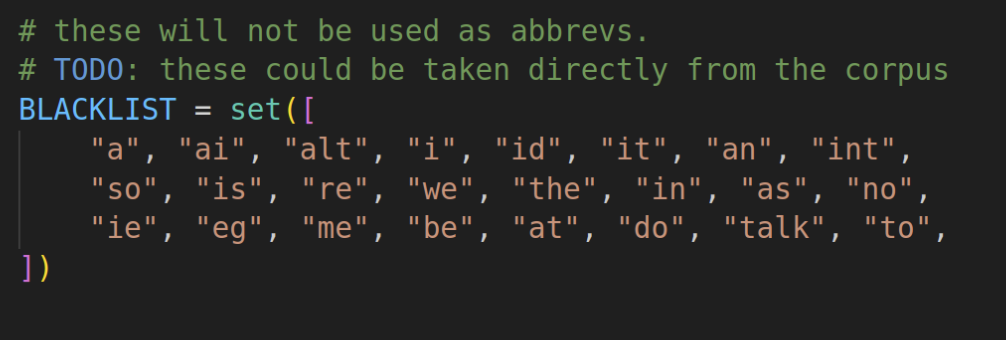 Fig 8. A manual blacklist is a simple trick, but worked surprisingly well
Fig 8. A manual blacklist is a simple trick, but worked surprisingly well
So how do I make my abbreviations memorable? This whole project won’t be worth anything if I don’t remember to use it while I write. I wrote a heuristic function that suggests abbreviations such as “the first letter of the word” or “first letter + last letter”, or “first two letters”. For multi-word phrases, acronyms are best.
 Fig 9. Some suggested abbreviations for “Remember”
Fig 9. Some suggested abbreviations for “Remember”
The script proceeds down the list of best phrases choosing the best available abbreviation for them. In the case of the word Remember, the shortcut robot -> r was already set because “robot” was higher on the list than “remember”, so the shortcut remember -> rr was chosen. If rr had also been taken, re would be blocked by my blacklist, and then rem would be chosen.
This prioritizes the most common phrases getting the best abbreviations! It might be better to do a global optimization of what abbreviations I want, but for now this works great.
Families of Abbreviations
You might have noticed that lots of phrases have overlap! The top example is “robot”, “robots”, “the robot” and “the robots”. Ideally the abbreviations for these phrases would be closely related to help me remember them.
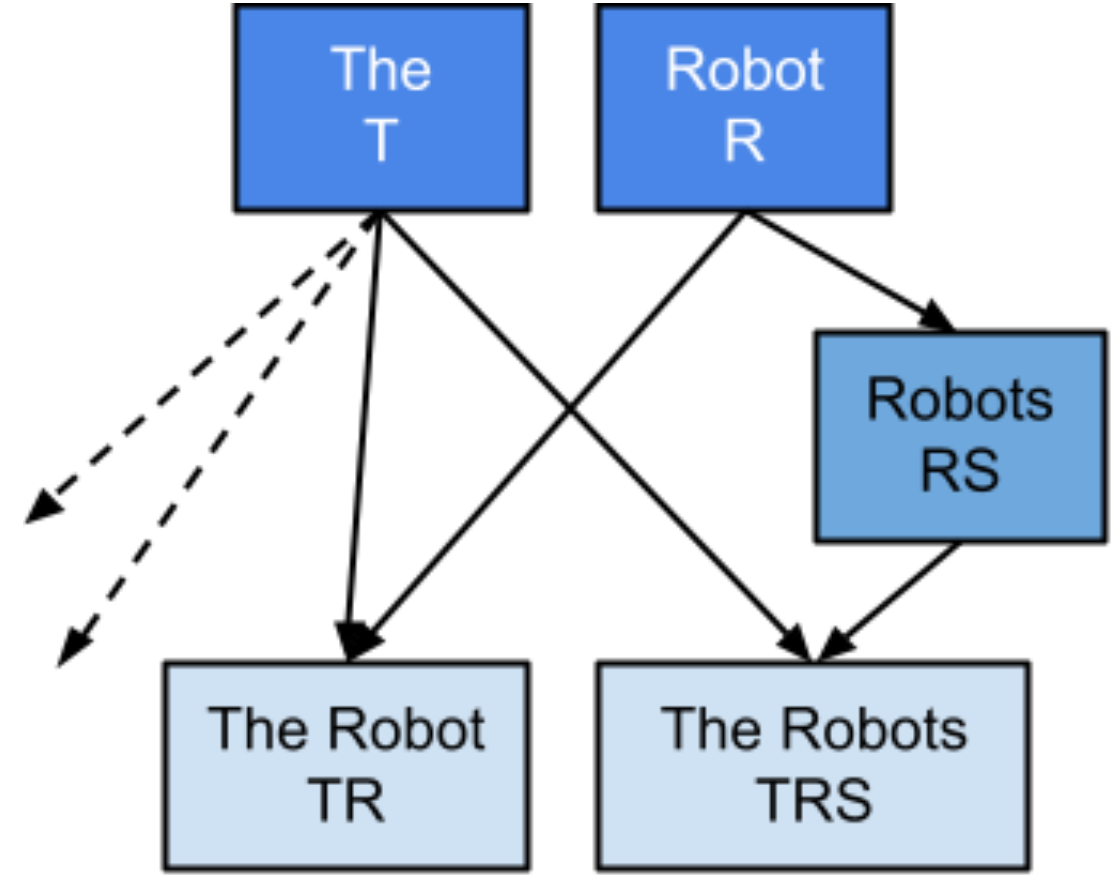 Fig 10. “Families” of abbreviations combining in a predictable way
Fig 10. “Families” of abbreviations combining in a predictable way
I get a lot of this “composability” for free out of my suggestion algorithm, by setting the top choice for multi word phrases to be their acronym. Because the top choice for single word phrases is the first letter, these compose into acronyms!
 Fig 11. Getting composability for free from my ranking of abbreviation heuristics
Fig 11. Getting composability for free from my ranking of abbreviation heuristics
This doesn’t work perfectly however. the robots would also try to map onto tr following the acronym rule, and there are related “families” that are actually all single words, such as [some, something, someone, somewhat].
I could go down the rabbit hole of trying to design algorithms to perfectly construct these families by matching substrings and explicitly differentiating between singular and plural words, but instead I just added the ability to manually input some preset abbreviations and the algorithm would fill in the rest.
So… Do you actually use this?
Yes! It’s been super useful, especially in slack which is where all of its “training data” came from.
It’s also been great for email, although there I had to manually add a bunch of shortcuts because my email language is fairly different from my slack language. My gmail shortcuts match my initial expectations of longer phrases much more than my slack shortcuts. I’m not sure if that’s just because I just created them manually, but I do certainly write more verbosely and “politely” in email than I do in slack.
How does it actually work on your computer?
I use a program called Autokey to turn these abbreviations into actual autocorrects on my computer! When I type:
t<space>
Autokey detects it and injects:
<backspace><backspace>the<space>
keyboard events, instantly replacing my abbreviation with the actual phrase! It also matches cases, so rs -> robots and Rs -> Robots etc. Also it’s not just triggered on <space> but any non-word character, so I don’t have to hit spacebar if I’m ending a sentence with an abbreviation. I have a script that reads in my list of shortcuts and generates config files for Autokey.
Autokey works well for Ubuntu 18, but on other operating systems you’ll need use a different tool for your shortcuts, such as TextExpander or AutoHotkey.
If you’re interested in trying it out on your own, all of my code is open source on github ![]() !
!
 Fig 12. What it feels like typing at >100WPM
Fig 12. What it feels like typing at >100WPM